Graph databases
They can be "native" - where the entire construction of the database from storage, management and query is based on the graph structure of the data. The relationships between entities are then data in their own right.
Either they use more traditional database constructs, (e.g. tables), and then have a Graph API layer on top
Anatomy of a native property graph database
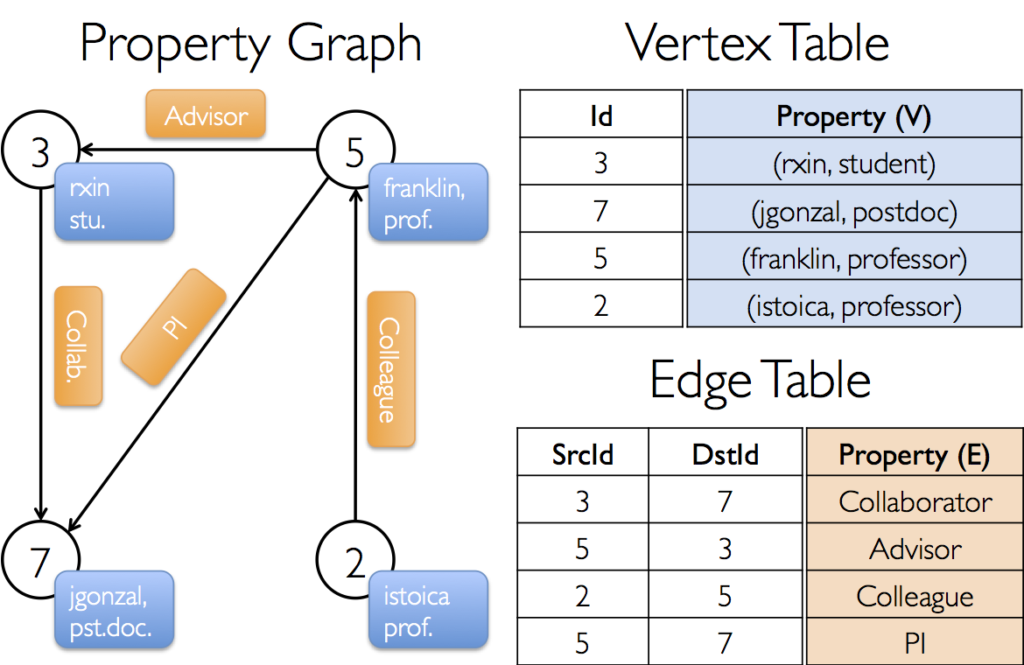
Graph databases
The graph is a mathematical model used to describe the relationships between entities. However, each complex network has intrinsic properties.
Properties are measured using specific metrics
- Integration metric This measures the degree of interconnection between two nodes/entities.
- Concepts of distance, path and shortest path
- Use case: Uber, which route to take to get to your destination in the shortest time?
- Metric of segregation Quantifies the presence of groups of interconnected nodes within a network: communities
- Identifies the formation of clusters
- Marketing use case: identifies groups of customers with common interests.
- Retail use case: which product is recommended based on the purchases of a similar customer profile?
- Centrality metric Evaluates the importance of a node in relation to others in a network.
- Social media use case: identify influencer profiles and measure the impact of their publications
- Resilience metric This is a measure of a network's ability to adapt and maintain its operational performance under difficult conditions.
- Use case: what impact on the electricity network in the event of a transformer failure?
Is my problem a graph problem?
No
- If the Data is disconnected and the relationships are not important
- If the queries are based on sequentially indexed data
- Where the data objects or data model remain static and the data structure is fixed and tabular
- When data queries perform bulk data analysis
- When using key-value storage
- When a large volume of text or BLOBS need to be stored as property.
Yes
- If the queries require a lot of entities (e.g.: large number of SQL tables, 360° vision...)
- Implies recursion (e.g. SQL SELF JOINS)
- If there are complex or even colliding hierarchies (e.g. SQL one-to-many, many-to-many)
- If the model is relationship-based (e.g. collaborative filtering, shared relationship counts, shortest path, cost/time minimisation, supply chain, financial flows...)
- Requires mapping across multiple data sources, direct or indirect (e.g. DataLake unification)
- Requires fast query results (e.g. digital applications, search engine...)