Les bases de données graphes
Elles peuvent être « natives » – où l’ensemble de la construction de la base de données depuis le stockage, la gestion et la requête repose sur structure graphe des données. Les relations entre les entités sont alors des données à part entière.
Soit elles utilisent des constructions de base de données plus traditionnelles, (ex :tables), puis disposent d’une couche API Graph au-dessus
Anatomie d’une base de données graphe de propriété native
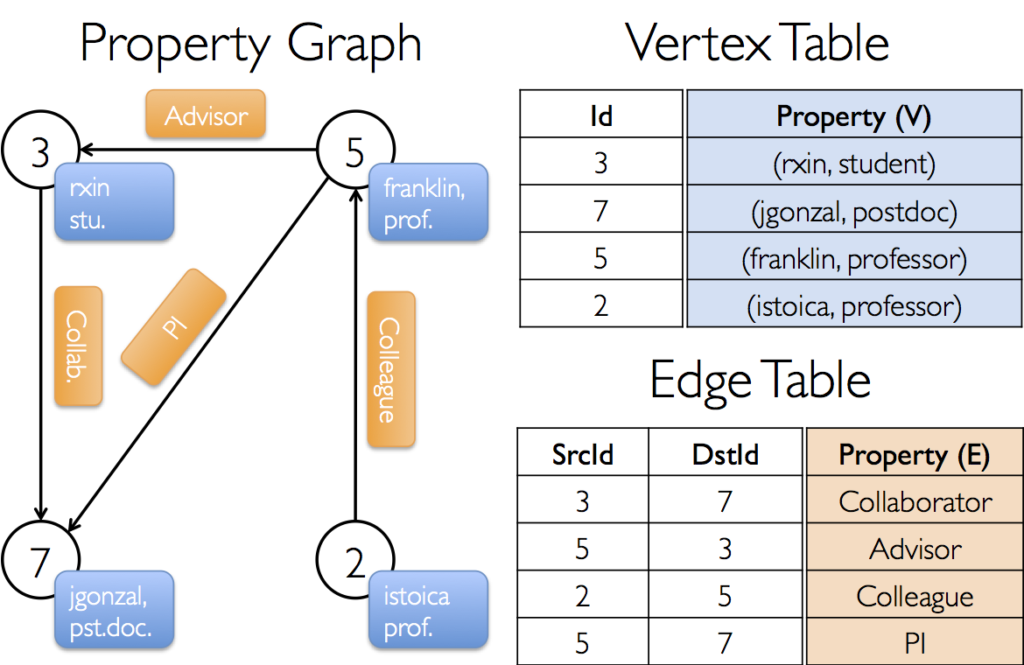
Les bases de données graphes
Le graphe est un modèle mathématique utilisé pour décrire les relations entre les entités. Cependant, chaque réseau complexe présente des propriétés intrinsèques.
Les propriétés sont mesurées à l’aide de métriques spécifiques
- Métrique d’intégration : mesure le degré d’interconnexion entre deux nœuds/entités.
- Concepts de distance, chemin et plus court chemin
- Cas d’usage : Uber, quelle route emprunter pour arriver à destination en un minimum de temps ?
- Métrique de ségrégation : quantifie la présence de groupe de nœuds interconnectés au sein d’un réseau : les communautés
- Identifie la formation de clusters
- Cas d’usage Marketing : identifie les groupes de clients avec des centres d’intérêts communs.
- Cas d’usage Retail : quel produit recommandé d’après les achats d’un profil client similaire ?
- Métrique de centralité : Evalue l’importance d’un nœuds par rapport aux autres au sein d’un réseau.
- Cas d’usage réseaux sociaux: identifier les profils influenceurs et mesurer l’impact de leurs publications
- Métrique de résilience : mesure la capacité d’un réseau à s’adapter et à maintenir ses performances opérationnelles dans des conditions difficiles.
- Cas d’usage : quel impact sur le réseau électrique en cas de panne d’un transformateur ?
Mon problème est-il un problème graphe ?
Non
- Si les Données sont deconnectées et les relations ne sont pas importantes
- Si les requêtes reposent sur des données indexées séquentiellement
- Lorsque les objets de données ou le modèle de données restent statique et la structure des données est fixe et tabulaire
- Lorsque les requêtes de données exécutent des analyses de données en masse
- Lorsqu’on utilise un stockage clé-valeur
- Lorsqu’un volume important de texte ou BLOBS ont besoin d’être stockés en tant que propriété.
Oui
- Si les requêtes nécessite beaucoup d’entités (ex : nombre important de tables SQL, vision 360°…)
- Implique la récursivité (ex : SQL SELF JOINS)
- S’il existe des hiérarchies complexes, voire en collision (ex : SQL one-to-many, many-to-many)
- Si le modèle est basé sur les relations (ex : « collaborative filtering », « shared relationship counts », plus court chemin, minimisation coût/temps, supply chain, flux financiers…)
- Nécessite un mapping à travers plusieurs sources de données, direct ou indirect (ex : unification de DataLake)
- Nécessite des résultats de requêtes rapides (ex : applications digitales, moteur de recherche…)